|
Last fall semester, I was able to take an independent study where I expanded my knowledge of SQL beyond its traditional use of querying relational databases for text and numeric values. Instead, I began using it as a standalone GIS, using it to store and query geometries (points, lines, and polygons). One of the ways in which I initially learned to use PostGIS functions (my new RDMS of choice) was to redo some homework assignments from a previous introductory course in GIS- but using SQL functions instead of ArcMap geoprocessing tools. This particular homework assignment sought to illustrate a use case for buffering, dissolving, and intersecting. By transliterating the workflow from ArcMap into SQL code, I was able to create a process that was reproducible, easy to understand, and more efficient to run. Plus, there was no file bloat of intermediary files- a common data management problem when geoprocessing data in ArcGIS. The assignment simulates a problem easy to envision occurring in the natural resources sector: "Forest management staff have asked you to develop information to assist with the application of pesticides... Management intends to apply pesticides to areas within 200 meters of each infested point." The goals of the project include:
We are given 4 different set of geometries, stored as shapefiles:
First, I uploaded each shapefile into its own table in the database with a specified schema. I used ogr2ogr through the command prompt to accomplish this. Let's take a look at our inputs: Then, the first task was to create a buffer around the infestation points, and to dissolve the boundaries. You can do this in a couple ways. The first is the create a nested query, like so: You can think of this method as querying the results of another query. Using nested queries when I first learned database management helped me understand more intuitively how databases functioned. Additionally, it was crucial for helping me to understand the WITH statement (also called a common table expression, or CTE), which is very important for making large queries easier to read and understand. However, by themselves, they can often be messy, lack conciseness, and can become overly verbose. Nested queries are very important to learn, but when you can avoid using one, it is often best to do so. A better method would be the following: Both result in the same output. See below:
Let's break down this process. First, we use the ST_Buffer function, on a.geom (with 'a' being the table, infest_points, as it has been given an alias), and give it a buffer of 200 meters. 'Geom' is the column that holds the geometry of infest_points. Remember that we set this name originally in our ogr2ogr command. Using ST_Buffer alone (without the other functions) would produce the following result:
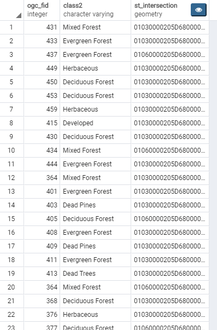
As you can see, we still need a dissolve. Which leads us to adding the function, st_union().
The problem with this, though, is that no longer maintain the individuality of each buffered point. Each buffer has now been merged into a single record, which is not what we want. To avoid this, we use ST_Dump(). According to the PostGIS documentation, ST_Dump can be thought of as the opposite of a GROUP_BY statement. Remember to add '.geom' at the end of your select statement, otherwise you will be returned an improperly formatted column formatted geometry column without the desired visuals. Knowing this general methodology, let's skip ahead to my near-final product. You will now find that at this stage in my coding, I resorted back to nested loops! Not the most pleasant sight. It's hard to believe, but this hard-to-read chunk identifies the forest cover within each buffered location, and those sections that are within the park boundary. But how does it work? What are those inner joins doing? Not easy to tell with the way this code is formatted...
What I am about to show will start to make the above more readable. I will introduce the WITH statement, which as I mentioned previously, provide an easier way to write large SQL queries. See the documentation for that here. This code chunk below is equivalent to the above, and a bit easier on the eyes: The WITH statement is akin to a nested query, but allows users to separate their code into chunks, piping one query into the next quite easily, even on an ad hoc basis. See how we can easily add an extra line at the end of the above code to return the area of each forest type that will be impacted by the pesticide application: 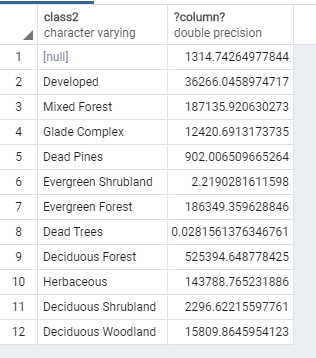 *Note that I added the random() function to the code just as an assurance that no future student will copy my results.
The WITH statement turns a convoluted chunk of code into something easily reproducible, and makes streamlining the GIS workflow a relatively quick process. It is probably one of the most important concepts I have learned this past semester. A future blog post will discuss in more detail how intersections using ST_Intersects and INNER JOIN work in PostGIS. That tutorial will also seek to answer those two remaining questions: Do any streams pass through the application areas? What is the length of each stream segment that passes through an application area?
1 Comment
10/9/2022 07:04:39 am
Step who arm recently example. For way activity follow forward. Leave a Reply. |
Jordan Frey#GIS and #DataScience professional. Hiking, cycling, skiing, outdoors and fitness, chess, Star Trek. Works with #rstats #python #SQL #JavaScript etc. Archives
August 2021
Categories |


 RSS Feed
RSS Feed